爬虫 - 反爬技巧
常见三大反爬方向
1、身份识别
(1)headers字段
User-Agent字段
反爬原理:爬虫默认情况下没有User-Agent,而是使用模块默认设置
解决方法:请求之前添加User-Agent即可,最好使用User-Agent池来解决可使用fake-useragent模块自动生成,官方文档:http://useragentstring.com/
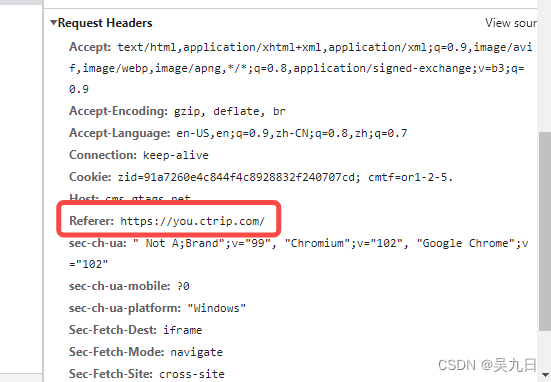
referer字段
反爬原理:爬虫默认情况下不会带上referer字段,服务器端通过判断请求发起的源头,以此判断请求是否合法
解决方法:添加referer字段如果请求头有带referer字段,添加上即可
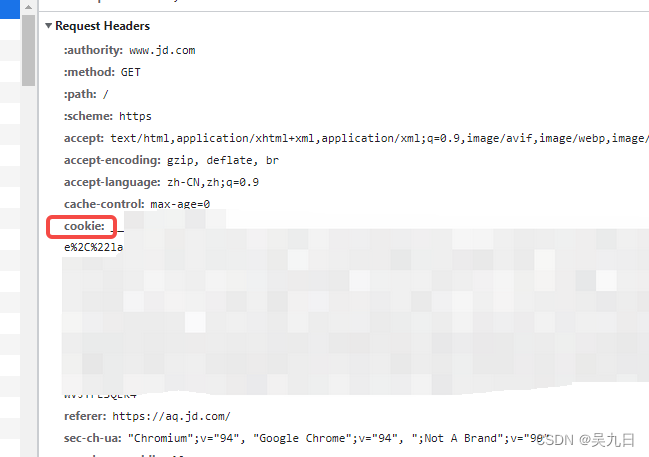
cookie
反爬原因:通过检查cookies来查看发起请求的用户是否具备相应权限,以此来进行反爬
解决方案:1、成功获取cookies之后模拟登录;2、通过post请求携带data模拟登录方法1:先登录,获取cookies之后模拟登录
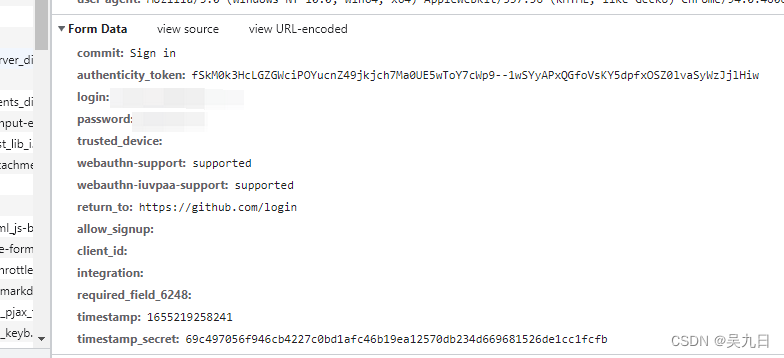
方法2:通过post请求携带data模拟登录
(2)请求参数
- html静态文件
反爬原因:请求参数为某个html文件内的参数
解决方案:利用search寻找相关html静态文件 - 发送请求
反爬原因:请求参数为已发送请求包的返回参数
解决方案:利用search寻找相关包 - js生成
反爬原理:js生成请求参数
解决方法:分析js,观察加密的实现过程,通过js2py获取js的执行结果 - 验证码
反爬原理:通过弹出验证码强制验证
解决方法:连接打码平台API或者使用机器学习的方法识别验证码
2、爬虫行为
(1)请求频率
- 同一ip/账号单位时间内总请求数量
反爬原理:同一个ip/账号大量请求对方服务器,会被识别为爬虫
解决方法:1、使用多ip代理(最好是高匿代理),搭建ip代理池;2、使用多账号 - 同一ip/账号请求间隔
反爬原理:请求间隔固定或请求时间间隔较短,会被识别为爬虫
解决方法:1、使用randam随机函数获取随机请求间隔,模拟真实用户操作;2、使用多ip代理(最好是高匿代理),搭建ip代理池;3、使用多账号,账号请求之间设置随机休眠 - 同一ip/账号每日请求次数
反爬原理:日请求次数超过服务器设定值,服务器拒绝响应
解决方法:1、使用多ip代理(最好是高匿代理),搭建ip代理池;2、使用多账号
(2)爬取过程
- js跳转
反爬原理:通过js实现页面跳转,无法在源码中获取下一页url
解决方法:抓包跳转后的页面,获取对应请求的url,分析其规律 - 陷阱
反爬原理:设置容易被爬虫语法规则获取的陷阱url,但正常用户无法获取,有效区分爬虫和正常用户
解决方法:仔细分析响应内容结构,找出页面中存在的陷阱 - 假数据
反爬原理:向返回的响应中添加假数据污染数据库
解决方法:核对数据库中数据同实际页面中数据的对应情况 - 阻塞任务队列
反爬原理:通过生成大量垃圾url,从而阻塞任务队列,降低爬虫的实际工作效率
解决方法:观察运行过程中请求响应状态,仔细分析源码,获取垃圾url生成规则,对url进行过滤 - 阻塞网络IO
反爬原理:发送请求获取响应的过程实际上就是下载的过程,在任务队列中混入一个大文件的url,当爬虫在进行该请求时将会占用网络IO,如果是有多线程则会占用线程
解决方法: 观察爬虫运行状态,对请求线程计时 - 运维平台综合审计
反爬原理:通过运维平台进行综合管理,通常采用复合型反爬虫策略,多种手段同时使用
解决方法: 根据上面的解决方案多方面处理
3、数据加密
(1)数据特殊化处理
自定义字体
反爬思路: 使用自有字体文件
解决思路:1、切换到手机版再进行分析;2、解析字体再进行翻译例:猫眼电影评分
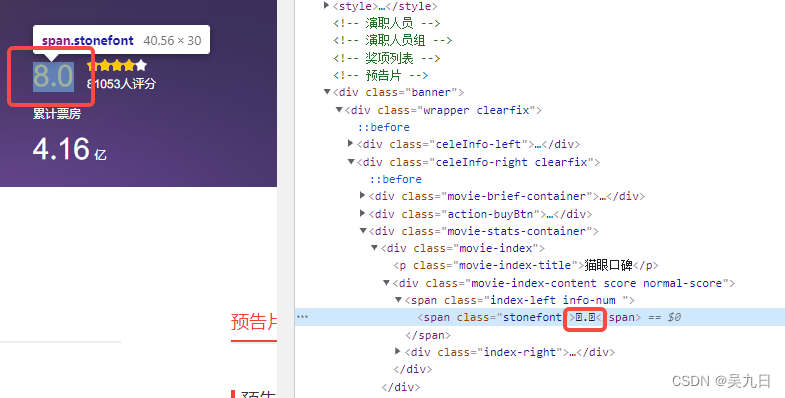
方法1. 切换到手机版后,字体可以直接获取
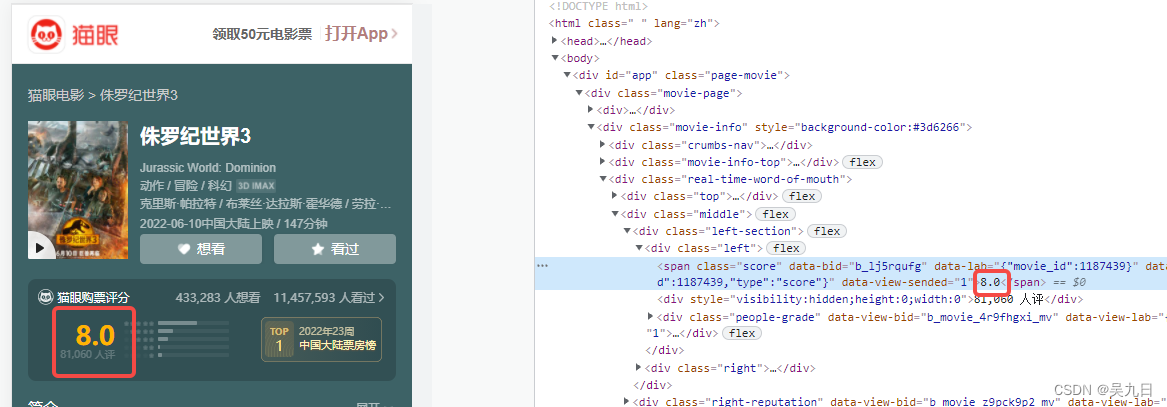
方法2. 找到对应文件进行字体解析
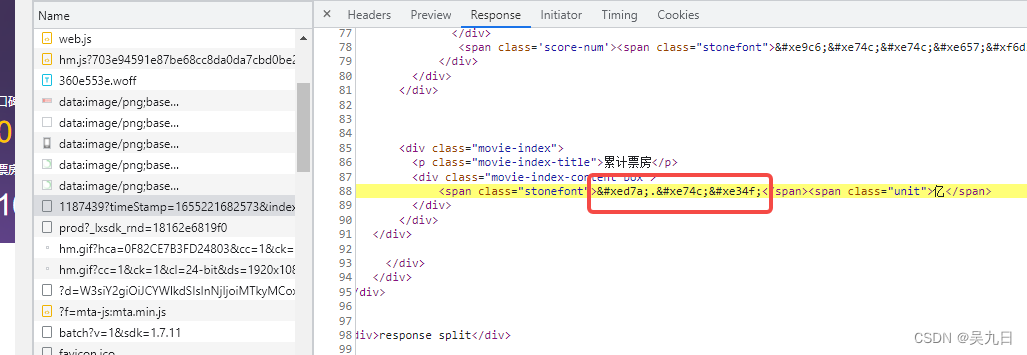
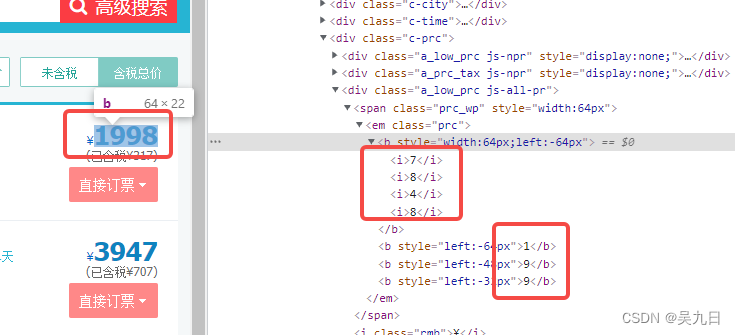
css偏移
反爬思路:源码数据不是真正数据,需要通过css位移才能产生真正数据
解决思路:计算css的偏移例:去哪儿网
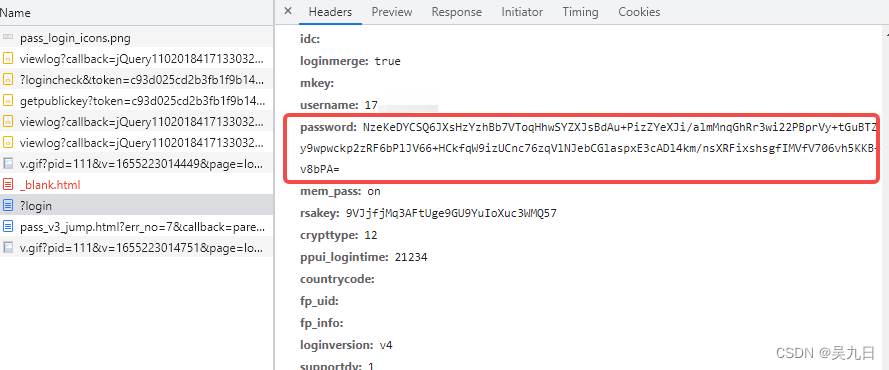
js动态生成数据
反爬原理:通过js动态生成
解决思路:解析关键js,获得数据生成流程,模拟生成数据例:登录时,post请求的password为加密数据
数据图片化
反爬原理:通过图片展示数据
解决思路:通过使用图片解析引擎从图片中解析数据编码格式
反爬原理: 不使用默认编码格式(通常爬虫使用utf-8格式进行解码)
解决思路:根据源码尝试多种格式解码
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 妙妙屋!